Beating GPT-3 with Only 0.1% of the Parameters
Performance similar to GPT-3 can be obtained with language models whose parameter count is several orders of magnitude smaller.


Our team recently got together to discuss the Pattern-Exploiting Training (PET), a deep-learning training technique for natural language processing (NLP) models developed by LMU Munich researchers Timo Schick and Hinrich Schütze. According to their paper on arXiv:
"In this work, we show that performance similar to GPT-3 can be obtained with language models whose parameter count is several orders of magnitude smaller. This is achieved by converting textual inputs into cloze questions that contain some form of task description, combined with gradient-based optimization; additionally exploiting unlabeled data gives further improvements."
GPT-3 is a breakthrough innovation and a monster of an AI system, it can do almost anything. The problem lies in the training. Parameters are variables used to tune and tweak AI models. The more parameters an AI model is trained with, the more robust we expect it to be. The GPT-3 model requires 175 billion parameters and 22 graphic processors that would cost somewhere between $4.6 million and $12 million to train.
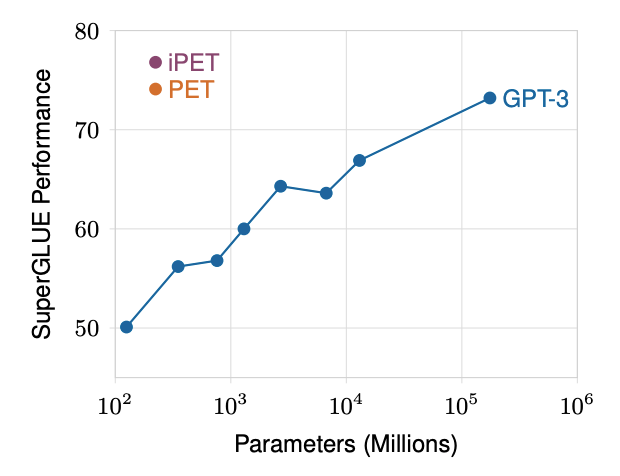
The researchers proposed an alternative transformer NLP model that is much more efficient than GPT-3. It outperformed GPT-3 on the SuperGLUE benchmark test using only 223 million parameters, a tiny fraction of GPT-3's parameters.
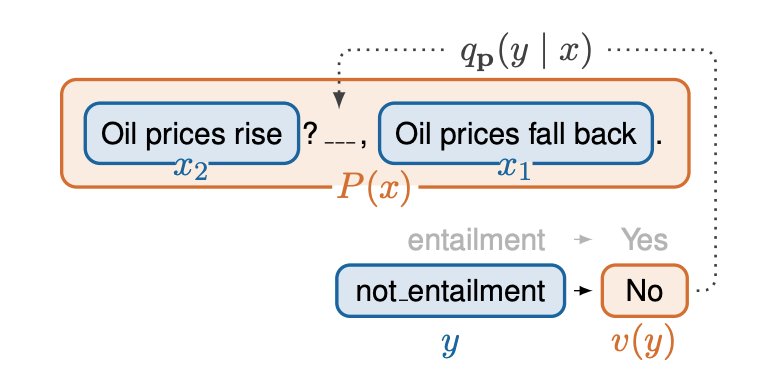
The team fuses the PET method with a small pre-trained ALBERT mode for which PET required pattern-verbalizer pairs (PVPs) to convert inputs into cloze questions and train an ensemble of models for different reformulations.
It certainly is a big deal that PET / iPET is able to exceed GPT-3's few-shot performance on the SuperGLUE benchmark with only 0.1% of GPT-3's parameters. While this doesn't mean that it can outperform GPT-3 in other tasks, it does open new ways for other researchers to venture into AI using more modest hardware. Schick and Schütze have open-sourced their PET code and FewGLUE dataset on GitHub.
Please check out our team's seminar on the PET / iPET here:
We are building our AI team and are looking for great talent to push AI boundaries. If you are passionate about AI, we would love to connect with you! Email us at jobs@allganize.ai.
Learn More About Allganize's Technology